Java基础文件与IO(一)
文件操作
java.io.File是Java提供的专门针对文件操作的类,File是文件与目录路径的一种抽象表示,用于操作文件与目录,不能操作文件内容。
构造File对象
一个File对象通常表示磁盘上一个真实存在的文件或目录,创建File对象时,无论对应的文件与目录是否存在,不会影响File对象的构造。
常用的三个构造File方法
| 方法 | 描述 |
|---|---|
| public File(String pathname) | 通过给定的路径名创建指定的File实例 |
| public File(String parent, String child) | 根据指定的父路径与子路径字符串创建File实例 |
| public File(File parent, String child) | 根据指定的父路径File与子路径字符串创建新的File实例 |
public static void main(String[] args) {
// 创建表示一个目录的File实例
File dir = new File("D://test");
// 创建表示文件的File实例
File sourceFile1 = new File("D://test", "source.txt");
// 根据父路径File实例创建新的File实例
File sourceFile2 = new File(dir, "source.txt");
}
常用的判断方法
| 方法 | 描述 |
|---|---|
| public boolean exists() | 判断文件或者目录是否存在 |
| public boolean isDirectory() | 判断File表示的路径是否是一个目录 |
| public boolean isFile() | 判断File表示的路径是否是一个文件 |
| public boolean isHidden() | 判断File是否是一个隐藏的文件与路径,即Unix以.开始命名的文件或目录, Window需要在文件系统中明确标记是否隐藏 |
| public boolean canRead() | 判断是否可读 |
| public boolean canWrite() | 判断是否可写 |
| public boolean canExecute() | 判断是否可执行 |
public static void main(String[] args) {
File hiddenSshDir = new File("D://test/hidden");
System.out.println(hiddenSshDir.isHidden()); // true
System.out.println(hiddenSshDir.isFile()); // false
System.out.println(hiddenSshDir.isDirectory()); //true
System.out.println(hiddenSshDir.exists()); // true
}
常用的获取属性方法
| 方法 | 描述 |
|---|---|
| public String getName() | 获取文件名或目录名,如source.txt |
| public String getAbsolutePath() | 获取文件或目录绝对路径 |
| public String getPath() | 获取文件或目录相对路径,如果构造File时指定的就是绝对路径, 则与getAbsolutePath返回内容一致,如果是相对路径,则以系统属性user.dir为目录创建 |
| public long length() | 返回文件内容大小,单位字节。如果File表示的是目录,则返回0 |
public static void main(String[] args) {
File sourceFile = new File("test/dir");
System.out.println(sourceFile.getName()); // dir
System.out.println(sourceFile.getAbsolutePath()); // D:\workspace\base-star-point\test\dir
System.out.println(sourceFile.getParent()); // test
System.out.println(sourceFile.getPath()); // test\dir
System.out.println(sourceFile.length()); // 0
}
操作文件方法
| 方法 | 描述 |
|---|---|
| public boolean createNewFile() | 创建文件,如果文件已经存在,则返回false |
| public boolean mkdir() | 创建目录 |
| public boolean mkdirs() | 创建目录,父路径中任何一级目录不存在都会自动创建,类似mkdir -p /data/test/dir 命令 |
| public boolean delete() | 删除文件或目录,如果File是一个目录,并且目录不为空,则无法删除, 文件或目录正被其他程序使用,也无法删除。 |
| public boolean renameTo(File dest) | 重命名文件,即移动文件 |
public static void main(String[] args) throws IOException {
File file = new File("D://test/txt");
boolean suc = file.createNewFile();
System.out.println(suc); // true,创建成功
suc = file.createNewFile();
System.out.println(suc); // false, 文件已经存在
suc = file.mkdir();
System.out.println(suc); // fasle, 相同路径名的文件已经存在,无法创建同名目录
File dir = new File("D://test/a/b/c");
suc = dir.mkdir();
System.out.println(suc); // false,无法创建目录c, 父目录D://test/a/b不存在
suc = dir.mkdirs();
System.out.println(suc); // true,整个目录D://test/a/b/c全部创建
}
重命名文件,将D://test/source.txt移动到D://test/sub目录,并命名为b.txt。
public static void main(String[] args) {
File source = new File("D://test/source.txt");
File dir = new File("D://test/sub");
dir.mkdir();
File target = new File("D://test/sub/b.txt");
System.out.println(source.renameTo(target));
}
创建临时文件,File提供了一个静态方法创建临时文件
// 未指定临时目录,使用系统属性java.io.tmpdir值作为临时目录
public static File createTempFile(String prefix, String suffix)
// 指定临时目录创建临时文件
public static File createTempFile(String prefix, String suffix, File directory)
创建临时文件时,可以指定系统临时目录,File类默认使用系统属性java.io.tmpdir( java -XshowSettings:properties -version 查看)值作为临时目录,后缀未填写则默认为.tmp。
public static void main(String[] args) throws IOException {
Properties properties = System.getProperties();
properties.forEach((k,v) -> System.out.println(k + "=" + v));
// C:\Users\SUNJINFU\AppData\Local\Temp\test-1385972536118005697.log
System.out.println(File.createTempFile("test-", ".log"));
}
遍历文件目录
| 方法 | 描述 |
|---|---|
| public String[] list() | 返回目录下子文件与子目录名,不是目录直接返回null |
| public String[] list(FilenameFilter filter) | 返回目录下符合文件名条件的子文件与子目录字符串名 |
| public File[] listFiles() | 与list方法类似,返回类型是File数组 |
| public File[] listFiles(FilenameFilter filter) | 返回目录下符合文件名条件的子文件或子目录File数组 |
| public File[] listFiles(FileFilter filter) | 返回目录下符合条件的子文件或子目录File数组 |
删除指定目录下的所有.txt文件
public static void main(String[] args) {
File file = new File("D://test");
// 通过name filter过滤出文件名后缀为.txt的文件
File[] files = file.listFiles((dir, name) -> name.endsWith(".txt"));
if (files != null) {
for (File f : files) {
f.delete();
}
}
}
删除目录,如果目录不为空,则需先遍历删除子文件、子目录
D:\test>tree /f
│ 1.log
│
├─a
│ a.txt
│
└─b
└─c
c.txt
public class DeleteDirectoryDemo {
public static void main(String[] args) {
File file = new File("D://test");
deleteFile(file);
}
public static void deleteFile(File file) {
// 判断文件是否存在
if (!file.exists()) {
return;
}
// 如果是文件,直接删除
if (file.isFile()) {
if (!file.delete()) {
System.out.println("failed to delete file: " + file.getAbsolutePath());
}
return;
}
// 如果是目录,则先遍历删除目录下文件或者子目录
File[] files = file.listFiles();
if (Objects.nonNull(files) && files.length > 0) {
for (File f : files) {
deleteFile(f);
}
}
// 最后删除目录
if (!file.delete()) {
System.out.println("failed to delete directory: " + file.getAbsolutePath());
}
}
}
Files
从Java7开始,在java.nio.file包下提供了一个文件或者目录操作工具类Files,Files的方法基本都是静态方法,该类不仅能操作文件,还能结合IO流操作文件内容。与File类相比,Files的很多方法都能明确的返回操作失败的异常信息,而不是只返回简单的true或者false。
如test目录不存在时直接使用Files创建source.txt
// Exception in thread "main" java.nio.file.NoSuchFileException: D:\test\source.txt
Files.createFile(Paths.get("D://test/source.txt"));
删除不存在的文件
// Exception in thread "main" java.nio.file.NoSuchFileException: D:\test\1.txt
Files.delete(Paths.get("D://test/1.txt"));
Files提供了非常丰富的方法,按功能分为如下几类方法
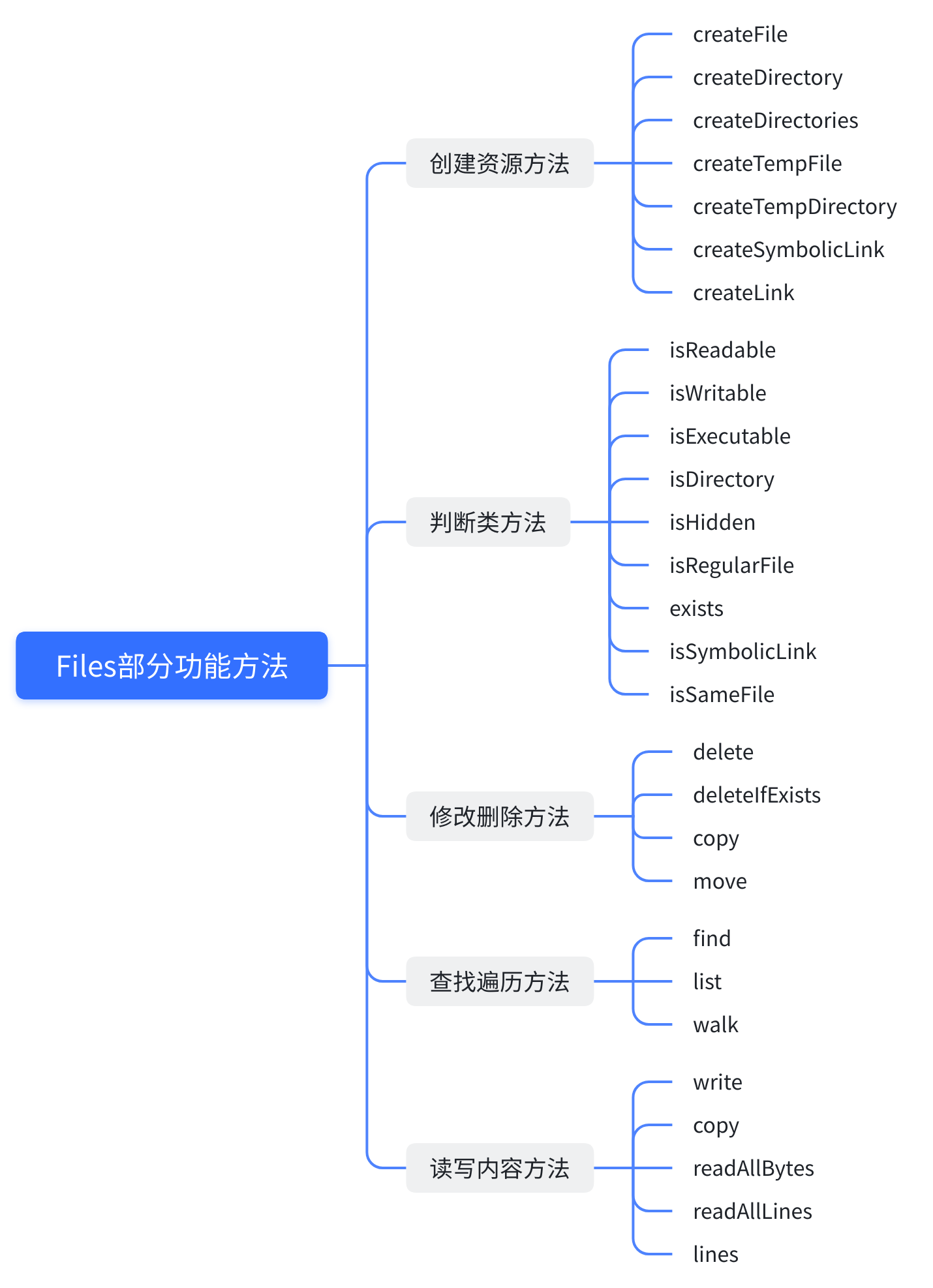
IO流
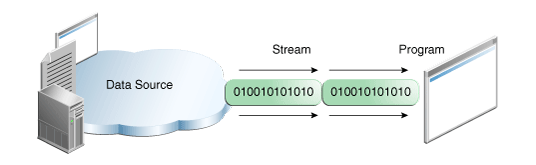
一个IO流代表了一个输入源(Input)以及对应的输出目的地(Output),其中包括磁盘文件、设备、程序、内存数组等。IO流的数据类型支持字节、原始数据类型、本地化字符以及对象等,不管什么数据类型,最终将这些数据转换成01二进制序列,一个IO流就是由一序列01数据组成。
程序可以从输入流(Input Stream)中读取数据
程序也可以通过输出流(Output Stream)将数据写到目的地
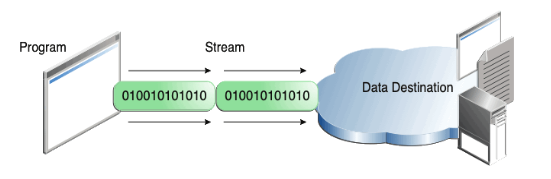
输入源与输出目标最常见的就是磁盘文件(文件IO)、网络socket(网络IO)以及内存字节数组。
字节流
字节流的输入输出都是以字节为单位处理数据,一个字节等于8个二进制位,即由8位0或1组成的序列,如01102300为一个字节。在Java中所有的字节流都是从抽象类InputStream或OutputStream类继承而来。大部分字节流使用方式相同,只是它们的构造方式可能不一样。
InputStream
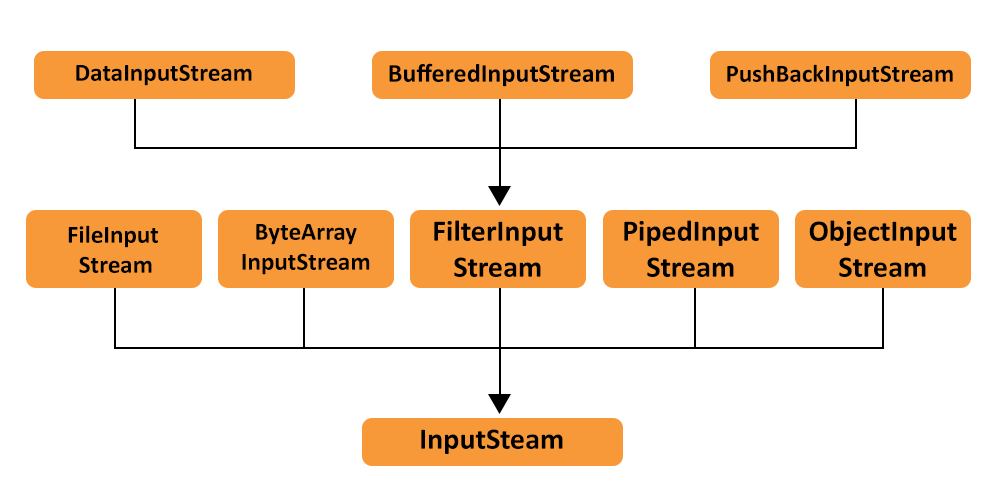
InputStream提供的方法
| 方法名 | 签名 | 描述 |
|---|---|---|
| read | public abstract int read() | 这是一个抽象方法,需要子类实现,用于从输入流中读取下一个字节数据。 由于一个字节是 8位,返回值介于0~255之间,如果没有可读数据,即达到了流的末尾,则返回-1。方法会一直阻塞直到有字节数据可读、到达流末尾或者发生IO异常。 |
| read | public int read(byte b[]) | 从输入流中读取b.length个字节,并储存到字节数组b中,如果b长度为0,则不会读取任何字节数据,方法返回0。read(byte b[]) -> read(byte b[], int off, int len) -> read |
| read | public int read(byte b[], int off, int len) | 从输入流中读取最多len个字节,如果len为0,不会读取任何字节数据,直接返回0,读取的字节从数组b的off位置开始存放。read(byte b[], int off, int len) -> read() |
| skip | public long skip(long n) | 跳过并丢弃输入流中的n个字节数据,通过调用read(byte b[], int off, int len)读取字节并丢弃。 |
| available | public int available() | 返回下一次操作时,输入流中预估的可读字节数量 |
| close | public void close() | 关闭输入流,释放与流关联的系统资源 |
| markSupported | public boolean markSupported() | 用于测试输入流是否支持mark与reset方法 |
| mark | public synchronized void mark(int readlimit) | 在输入流中标记当前位置,标记位置后,还可以读取最多readlimit字节,后续可以通过reset方法回到上一次mark的位置,达到重复读取相同字节数据的操作,使用mark方法,则markSupported必须返回true,在关闭的流中调用mark方法,不会有任何效果。 |
| reset | public synchronized void reset() | 在流中复位,回到上一次调用mark方法标记的位置,如果未发现任何mark或者上一次mark标记后读取的字节数超过readlimit,则发生IOException,使用reset方法,则markSupported必须返回true。 |
InputStream中的方法大部分都是一种规范,最终的字节流子类某些方法可能会有所不同。
OutputStream
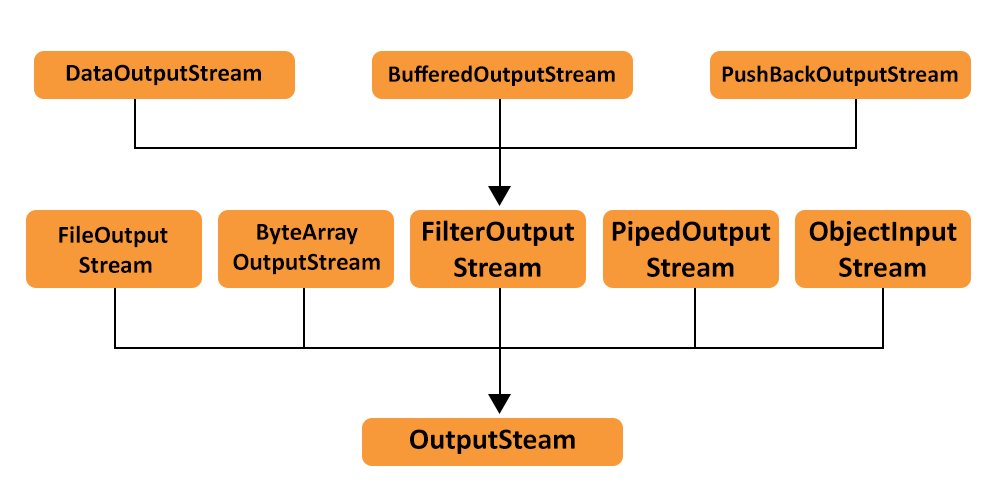
OutputStream提供的方法
| 方法名 | 签名 | 描述 |
|---|---|---|
| write | public abstract void write(int b) | 这是一个抽象方法,需要子类实现,用于将指定的字节数据写入到输出流中,在Java中int是32位,4个字节,write方法实际写入的只是整型数据b的低8位,其余24位直接忽略。 |
| write | public void write(byte b[]) | 将字节数组b中的数据写入到输出流中。write(byte b[]) -> write(byte b[], int off, int len) -> write() |
| write | public void write(byte b[], int off, int len) | 从字节数组b下标为off的位置开始,将len个字节数据写入到输出流中。write(byte b[], int off, int len) -> write() |
| flush | public void flush() | 刷新输出流,强制一些缓冲输出流将内部缓冲的一些字节数据立即写入目标地,如果目标地是磁盘文件,调用flush方法后,并不保证文件马上更新,这取决于操作系统。 |
| close | public void close() | 关闭输出流,释放与流关联的系统资源 |
操作使用
文件IO字节流FileInputStream、FileOutputStream是使用最广泛的两个类,以这两个类进行操作说明。
public class CopyBytes {
public static void main(String[] args) throws IOException {
FileInputStream fis = null;
FileOutputStream fos = null;
try {
// 文件数据输入流,如果文件不存在或者是一个目录,则发生FileNotFoundException
fis = new FileInputStream("D://test/source.txt");
// 数据输出流,目标文件不存在,大部分系统都会自动创建,如果文件已存在,则覆盖文件中已有内容
fos = new FileOutputStream("D://test/target.txt");
int c;
// 如果返回-1,表示已经读到流的末端
while ((c = fis.read()) != -1) {
// 如果是ascii字符,每个字符对应的整型值一定是0~127,
// 如果是汉字,而一个汉字由多个字节组成,因此会输出多个整型数据,128~255
System.out.print(c + " ");
fos.write(c);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
// 从输入流读取数据完成后,一定要关闭流,释放系统资源
if (fis != null) {
fis.close();
}
// 将数据写入输出流完成后,一定要关闭流,释放系统资源
if (fos != null) {
fos.close();
}
}
}
}
注意:IO流操作完成后,一定要在finally语句块中进行关闭。 Java7开始提供了try-with-resources语法,编译器识别该语法后,在字节码文件中自动生成了对应的finally语句块,并在语句块中关闭对应的流。
try (...) {
...
} catch (Exception e) {
...
}
用try-with-resources语法读写文件代码
public class CopyBytes2 {
public static void main(String[] args) {
try (FileInputStream fis = new FileInputStream("D://test/source.txt");
FileOutputStream fos = new FileOutputStream("D://test/target.txt")) {
int c;
// 内容长度(可读取的字节数量)
System.out.println("内容有效字节数: " + fis.available());
while ((c = fis.read()) != -1) {
System.out.print(c + " ");
fos.write(c);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
如source.txt文件有如下字符内容:I2023,我 ,文件编码为UTF-8时输出9个字节(汉字占用了三个字节)。
输出结果: 73 50 48 50 51 44 230 136 145
最后三个大于127的十进制值则表示汉字 我,其余的对应的是ascii字符。
FileOutputStream可以控制字节内容写入起始位置
- 通过 new FileOutputStream(“D://test/target.txt”) 构造输出流,每次从文件开头写入字节数据,因此会覆盖上一次打开文件时写入的内容。
public class FileOutputStreamDemo {
public static void main(String[] args) {
try (FileOutputStream fos = new FileOutputStream("D://test/target.txt")) {
String s = "2023,Baby 加油努力干";
// 调用FileOutputStream的write(byte b[])方法,写入多个字节
fos.write(s.getBytes(StandardCharsets.UTF_8));
} catch (IOException e) {
e.printStackTrace();
}
}
}
- 通过 new FileOutputStream(“D://test/target.txt”,
true) 构造输出流,每次从文件末尾写入字节数据,相当于向文档中追加数据内容,多次运行上述main方法,会发现D://test/target.txt文件内容增加。
字节流是IO流中最底层的低水平操作流,文件中包含的是字符数据,更高效的方法是通过字符流进行操作。
字符流
Java采用Unicode规范处理字符,字符流IO自动将Java内部字符格式与本地字符集进行转换,自动解码编码,因此比起直接使用IO字节流,字符流操作相对更简单高效,所有的字符操作流都是从抽象类Reader以及Writer继承而来。
字符编码
字符都有编码,读写字符时的编码不一致,则容易出现乱码,因此首先需要简单了解下常见的字符编码规则。
ASCII码
ASCII是American Standard Code for Information Interchange缩写,称为美国信息交换标准代码。ASCII一共定义了128个字符,其中33个字符是不可显示的控制字符,95个可显示的字符。
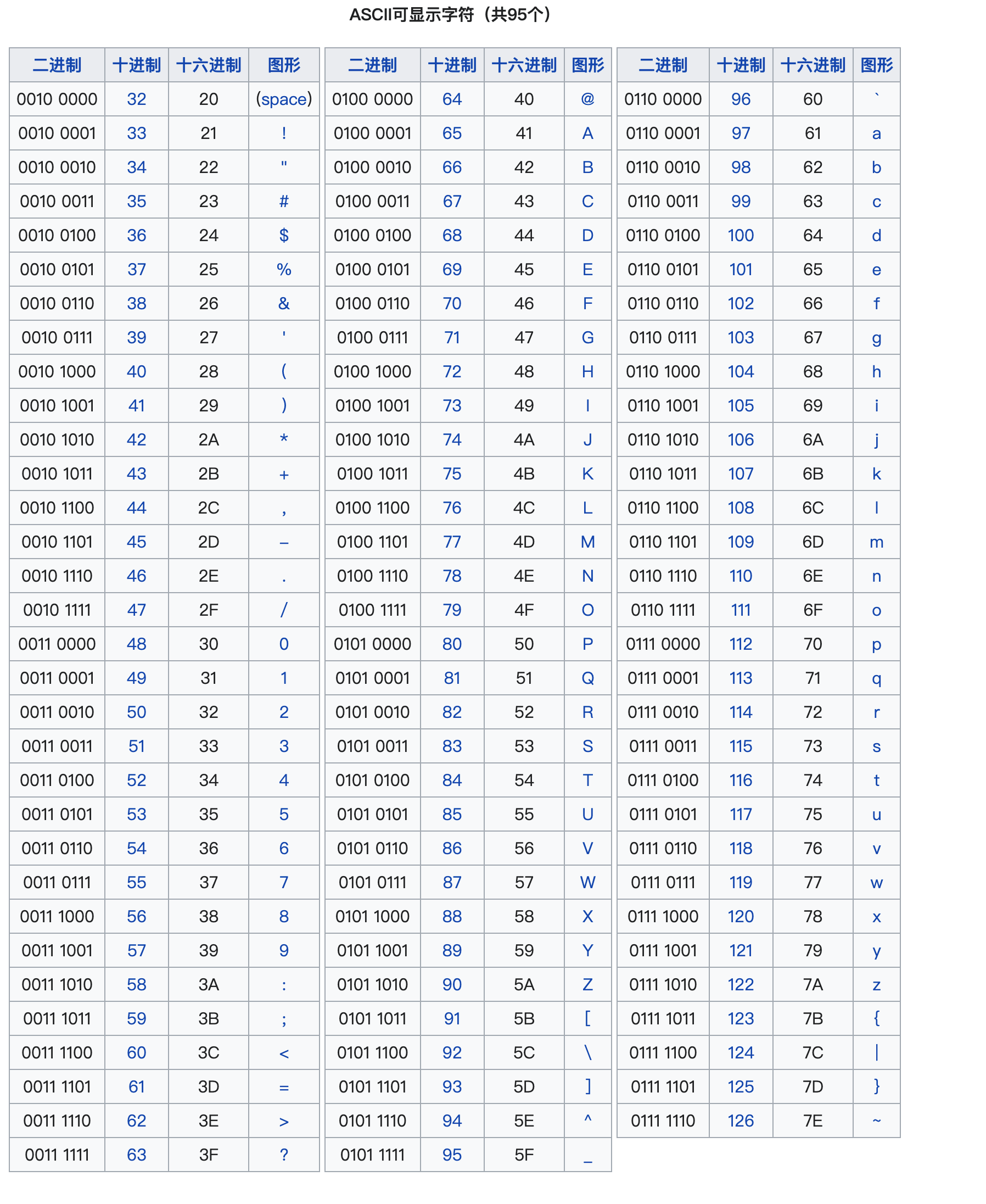
一个字节占8位,2^8=256,即一个字节可表示256个字符(0~255),而ASCII字符只有128个,因此一个字节的低7位,2^7=128,足以表达全部的ASCII字符(0~127),128~255则预留扩展其它字符,但128位根本不足以表示其它国家的字符。
GBK
GBK全称汉字内码扩展规范,GBK一共收集了
2万多汉字与字符,一个中文字符编码成2个字节进行存储。GBK兼容了ASCII字符集
假定有字符串: 我a你
按照GBK编码规范,最终需要5个字节来存储。
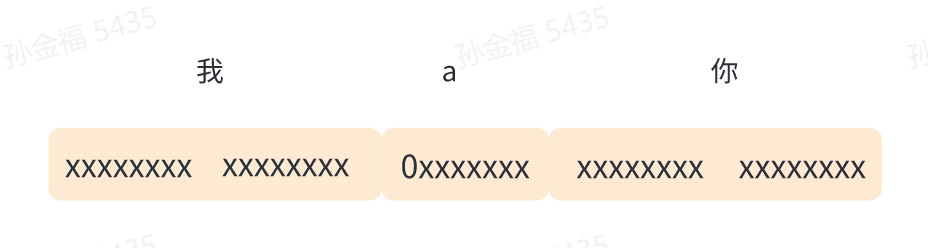
那上面5个字节,怎么能确定是5个ASCII码,还是包含中文字呢?GBK规定中文字符第一个字节第一位必须是1。
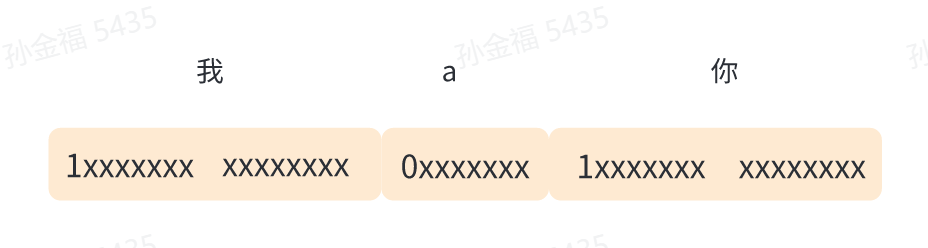
当程序采用GBK编码读取上面5个字节时,发现字节最高位是1时,还需再读下一个字节,然后将2个字节作为一个整体进行解码。GBK编码只用了高位字节的一位用作特殊标记,余下15位可用于表示字符集,即一共可表示2^15=32768个字符。
GBK是从GB2312编码规范上扩展的,而中国的汉字与符号有数十万,显然GBK也是不够的,因此又出现了GB18030, 按照字符集表示范围GB18030 > GBK > GB2312。
Unicode
各个国家都有自己的编码,当计算机信息在国际上进行交换时,就会出现问题,如用GBK编码的字节数据发送给A国家,A国家采用A国码解码肯定就出现了乱码,此时国际标准组织就制定了一套通用的字符集Unicode,即统一码,也叫万国码。Unicode字符集收纳了世界上所有文字、符号,统一进行编号。
UTF-8
Unicode只是一种字符集,并不是编码方案,没有编码方案则无法存储。Unicode字符集出现最早的编码方案是UTF-32,它规定所有的字符都采用固定的4个字节来表示,4个字节32位,可以表示42亿字符,足以支撑Unicode字符集。即使只需一个字节的ASCII字符a(二进制0110 0001 ),也必须用4个字节表示,前三字节直接补0。

UTF-32采用固定字节编码,程序处理简单,但是占用空间太大,基本很少使用,此时国际标准组织推出了Unicode编码方案UTF-8。
UTF-8针对Unicode字符集采取可变长编码方案,共分为四个长度区,1~4个字节英文、数字等只占用
1个字节(兼容标准的ASCII编码),汉字字符占用3个字节
UTF8编码示例
| UTF-8编码方式(二进制) |
|---|
0xxxxxxx (ASCII码) |
110xxxxx 10xxxxxx |
1110xxxx 10xxxxxx 10xxxxxx |
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
中文字 我 unicode码是\u6211,这是十六进制,转换成二进制是 0110 0010 0001 0001,按照UTF-8中文字三字节编码。
0110 001000 010001
按三字节填充后
11100110 10001000 10010001
最终中文 我 字UTF-8编码后存储的十六进制数据为 E6 88 91,通过文本工具Notepad以十六进制模式查看验证。
结论:UTF-8编码的汉字比GBK编码占用空间会更大。
Reader
Reader读取字符流,子类必须实现read、close方法,大部分子类会覆盖Reader中方法,提供更高效的操作或者一些额外的功能。
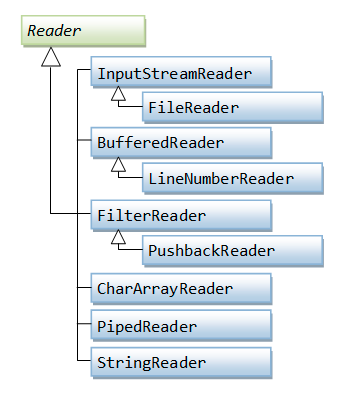
Reader提供的方法
| 方法名 | 签名 | 描述 |
|---|---|---|
| read | abstract public int read(char cbuf[], int off, int len) | 抽象方法,子类必须实现,读取字符到字符数组cbuf,并从数组off位置开始存储,最多读取len个字符。方法会阻塞直到有有效字符可读取、IO错误或者读取流结束。 |
| read | public int read(java.nio.CharBuffer target) | 读取字符并存储到字符缓冲区,如果读取到达了字符末尾,则返回-1。read(java.nio.CharBuffer target) -> read(char cbuf[], int off, int len) |
| read | public int read() | 读取单个字符,返回值范围0~65535(2^16),-1表示流读取完毕。 read() -> read(char cbuf[], int off, int len) |
| skip | public long skip(long n) | 跳过并丢弃输入流中的n个字符数据,该方法也是通过调用int read(char cbuf[], int off, int len)达到操作目的。 |
| ready | public boolean ready() | 测试流是否已就绪可读,返回true保证下一次的read()调用不会阻塞,返回false不保证下次调用一定会阻塞。 |
| close | abstract public void close() | 抽象方法,子类必须实现,关闭输入流,释放与流关联的系统资源 |
| markSupported | public boolean markSupported() | 用于测试输入流是否支持mark与reset方法 |
| mark | public void mark(int readAheadLimit) | 在输入流中标记当前位置,标记位置后,还可以读取最多readAheadLimit字符,后续可以通过reset方法回到mark位置,则markSupported必须返回true,在关闭的流中调用mark方法,不会有任何效果。 |
| reset | public void reset() | 在流中复位,回到上一次调用mark方法标记的位置,如果未发现任何mark则回到相应的位置如起点,使用reset方法,则markSupported必须返回true。 |
Writer
Writer用于将字符写入到字符流中,子类必须实现write、flush、close方法,大部分子类会覆盖Writer中方法,提供更高效的操作或者一些额外的功能。Note: 下图中少了一个常用的PrintWriter
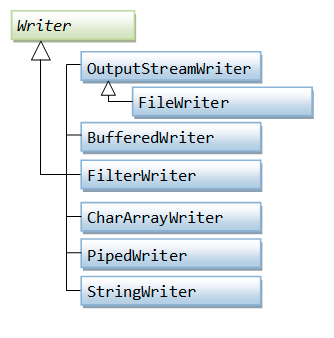
Writer提供的方法
| 方法名 | 签名 | 描述 |
|---|---|---|
| write | public abstract void write(char cbuf[], int off, int len) | 这是一个抽象方法,需要子类实现。将字符数组cbuf从下标off开始的字符写入到输出流中,最多写入len个字符。 |
| write | public void write(char cbuf[]) | 将字符数组中全部字符写入到输出流中。 write(char cbuf[]) -> write(char cbuf[], int off, int len) |
| write | public void write(int c) | 将单个字符写入到输出流中,由于int是4个字节32位,该方法实际只写入int的低16位,高16位被丢弃。write(int c) -> write(char cbuf[], int off, int len) |
| write | public void write(String str, int off, int len) | 将字符串中off位置开始的的部分字符写入到输出流中,最终调用的方法是write(char cbuf[], int off, int len) |
| write | public void write(String str) | 将字符串str中字符全部写入到输出流中。 write(String str) -> write(String str, int off, int len) |
| append | public Writer append(char c) | 附加指定的字符到Writer,实际调用的是write(int c) |
| append | public Writer append(CharSequence csq) | 附加指定的字符序列到Writer,实际调用的是write(String str) |
| append | public Writer append(CharSequence csq, int start, int end) | 附加指定字符序列中的部分字符到Writer |
| flush | abstract public void flush() | 抽象方法,刷新输出流,将流中缓冲的字符立即写到目标,如果输出流目标是另一个字符或者字节流,整个流形成的链都会被立即刷新。 |
| close | public void close() | 先刷新流,再关闭输出流,释放与流关联的系统资源,close一个已关闭的流,不会发生任何影响。 |
操作使用
一个字符流通常包装一个字节流,通过字节流去实现底层物理IO操作,字符流处理字符与字节之间的数据转换。在Java中有两个通用的字节到字符的桥接流,InputStreamReader与OutputStreamReader。
public class CopyCharacters {
public static void main(String[] args) {
try (InputStreamReader isr = new InputStreamReader(
new FileInputStream("D://test/source.txt"));
OutputStreamWriter osw = new OutputStreamWriter(
new FileOutputStream("D://test/target.txt"))) {
int c;
while((c=isr.read()) != -1) {
System.out.println(c);
osw.write(c);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
从字符输入流中读取数据

将数据写入字符输出流中

上述main方法在构造字符输入输出流时,未明确指定读写字符编码,字符流最终采用的是系统平台默认编码。
Windows中文系统默认是
GBKLinux系统默认是
UTF-8
Java在安装时,根据系统编码自动设置Java系统属性,通过如下命令查看Java系统属性
java -XshowSettings:property -version
Java系统属性值中有2个与编码相关的属性
file.encoding:这个非常重要,在Java中读取文件、URLEncode、字符串数据编码等都与此属性有关。sun.jnu.encoding:不用关注,用于JVM查找加载class的类名路径编码等
注意:在Windows下开发时,使用Java命令查看Java系统属性时,file.encoding=GBK,当使用IDEA工具开发项目时,通过IDEA给项目又设置了UTF-8编码,最终IDEA运行Java程序时,会通过-Dfile.encoding=UTF-8去覆盖默认的编码。当开发过程中遇见字符乱码时,需要关注JVM实际运行时的系统属性,也可通过代码获取。
String fileEncoding = System.getProperty("file.encoding")
指定字符编码构造字符输入输出流
// 指定UTF-8编码读字符数据
new InputStreamReader(new FileInputStream("D://test/source.txt"), StandardCharsets.UTF_8));
// 指定UTF-8编码写字符数据
new OutputStreamWriter(new FileOutputStream("D://test/target.txt"), StandardCharsets.UTF_8))
读写字符数据时编码必须保持一致,否则会出现字符乱码。
在中文Windows上使用记事本新建D://test/source.txt文件,写入 2024,加油努力干 ,然后以ANSI编码保存,在Windows中文系统上ANSI处理中文时就是GBK。
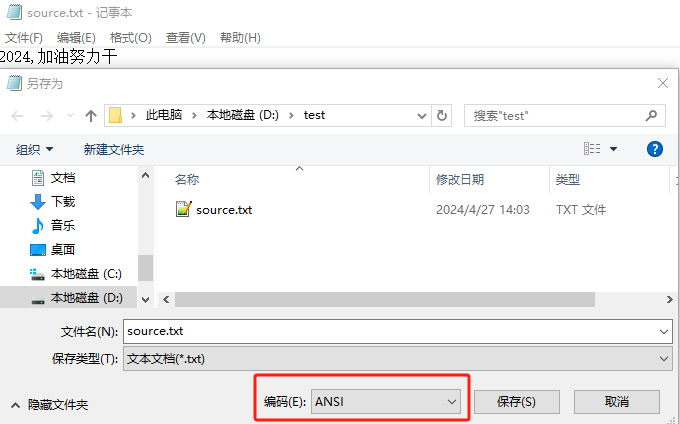
然后使用InputStreamReader字符流以UTF-8编码读取字符内容,使用OutputStreamWriter将字符数据写入到D://test/target.txt。
public class CopyCharactersWithCharset {
public static void main(String[] args) {
try (InputStreamReader isr = new InputStreamReader(
new FileInputStream("D://test/source.txt"), StandardCharsets.UTF_8);
OutputStreamWriter osw = new OutputStreamWriter(
new FileOutputStream("D://test/target.txt"))) {
int c;
while((c=isr.read()) != -1) {
System.out.println(c);
osw.write(c);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
代码运行后,查看文件D://test/target.txt内容出现乱码
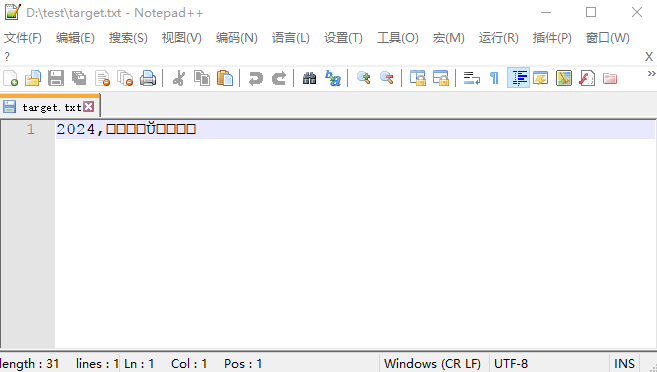
出现乱码的原因是InputStreamReader读取字符的编码与字符存储时编码不一致导致的,与OutputStreamWriter无任何关系,构造InputStreamReader时指定GBK编码后,再次运行则不会出现字符乱码。
// 指定GBK,StandardCharsets类中定义的都是标准的字符集编码
new InputStreamReader(new FileInputStream("D://test/source.txt"), "GBK"))
处理String时也需要关注编码
public class StringEncodeDemo {
public static void main(String[] args) throws Exception {
String fileEncoding = System.getProperties().getProperty("file.encoding");
System.out.println("JVM默认编码: " + fileEncoding);
String str = "2024,加油努力干";
System.out.println(new String(str.getBytes(), "GBK"));
}
}
代码输出如下
JVM默认编码: UTF-8
2024,鍔犳补鍔姏骞�
为何乱码?
str.getBytes()方法实际调用的是str.getBytes(“UTF-8”),存储时用的是UTF-8,读取字符时用的是GBK,字符读写编码不一致出现字符乱码。
强烈推荐统一采用UTF-8编码,使用IDEA编写Java代码时,必须设定编码,File -> Settings -> Editor -> File Encoding,或者通过-Dfile.encoding=UTF-8设定。
Java中还提供了FileReader、FileWriter简化了从文件读写字符,其内部自动封装包裹了对应的文件字节流,但是采用FileReader、FileWriter时只能使用JVM默认编码,无法单独设置读取字符的编码,因此统一编码非常重要。
// InputStreamReader从文件读取字符内容
new InputStreamReader(new FileInputStream("D://test/source.txt"), StandardCharsets.UTF_8));
// OutputStreamWriter将字符内容写入文件
new OutputStreamWriter(new FileOutputStream("D://test/target.txt"), StandardCharsets.UTF_8))
使用FileReader、FileWriter读写字符内容
public class CopyFileCharacters {
public static void main(String[] args) {
try (FileReader fr = new FileReader("D://test/source.txt");
FileWriter fw = new FileWriter("D://test/target.txt")) {
// 查看FileReader读取字符编码
System.out.println(fr.getEncoding());
// 查看FileWriter写入字符编码
System.out.println(fw.getEncoding());
int c;
while ((c = fr.read()) != -1) {
System.out.println(c);
fw.write(c);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
如果需要追加内容到文件中,请使用FileWriter带有两个参数的构造方法,第二个参数设置为true即可
public FileWriter(File file, boolean append)
// 第二个参数为true,字符内容会从文件末尾开始写入
FileWriter fw = new FileWriter("D://test/target.txt", true);
字符流IO经常会以更大单位读取字符,最常用的就是按行读取字符。一行包括一系列字符组成的字符串以及末尾的行结束符,行结束符可以是回车换行符\r\n,也可以是单个回车键字符\r,或者单个换行符\n。不同的操作系统,其换行符可能有所不同。
- Dos、Windows采用回车+换行符(CR+LF)表示下一行,即字符表现形式
\r\n - Unix、Linux采用换行符(LF)表示下一行,字符表现形式为
\n - Mac采用回车符(CR)表示下一行,字符表现形式为
\r
CR回车符ascii码十进制为13, 换行符ascii码十进制为10。支持按行读写的字符流有BufferedReader、BufferedWriter、PrintWriter等,根据操作系统自动处理行结束符。
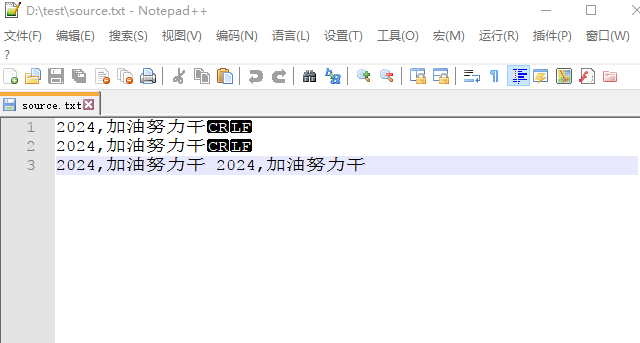
BufferedReader按行读取D://test/source.txt字符内容
public class BufferedReaderDemo {
public static void main(String[] args) {
try (BufferedReader br = new BufferedReader(new FileReader("D://test/source.txt"))) {
String line;
// 按行读取,自动处理回车换行符
while((line = br.readLine()) != null) {
System.out.println(line);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
代码运行后输出
2024,加油努力干
2024,加油努力干
2024,加油努力干 2024,加油努力干
BufferedWriter按行将字符写入D://test/target.txt
public class BufferedWriterDemo {
public static void main(String[] args) {
try (BufferedWriter bw = new BufferedWriter(new FileWriter("D://test/target.txt"))) {
bw.write("2024,加油努力干");
// 自动获取操作系统换行符写入到文件中
bw.newLine();
// 写入空行
bw.newLine();
bw.write("2024,加油努力干");
// 写入结束,最后一行后未添加换行符
bw.flush();
} catch (IOException e) {
e.printStackTrace();
}
}
}
Windows下使用Notepad查看文件内容,视图中选择显示行尾符,Notepad文本视图中的CR LF只是一种控制字符展示形式,并不是实际的CR LF字符,发现十进制值13展示CR,10展示LF。
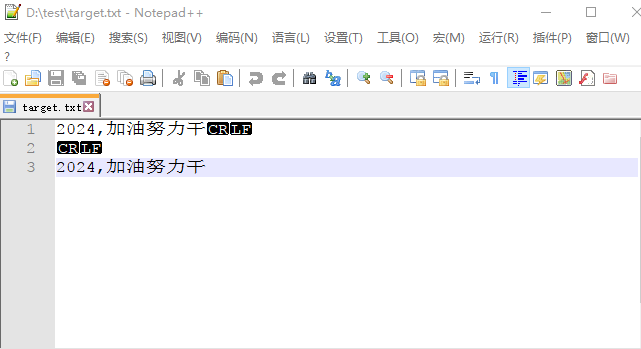
Nodepad上用十六进制查看数据
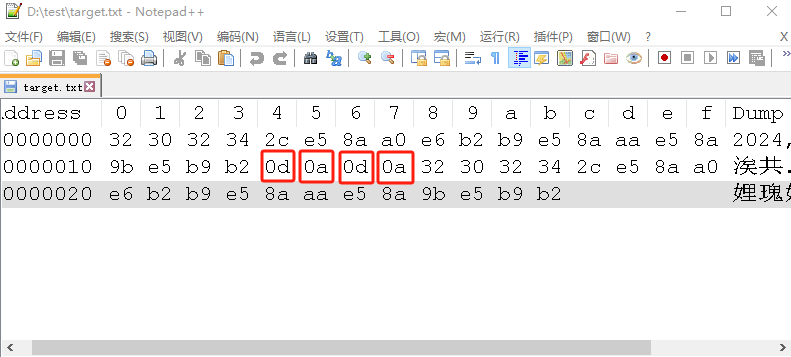
BufferedWriter.newLine()控制换行,实际调用的就是write(”\r\n”)写入换行
bw.write("2024,加油努力干");
// 与newLine()方法达到一样的换行效果
bw.write("\r\n");
bw.write("\r\n");
bw.write("2024,加油努力干");
bw.flush();
BufferedWriter每次写完字符内容时,需要显式调用插入换行符操作,因此Java提供了一个使用更广泛的PrintWriter字符输出流,PrintWriter中提供了一个println()方法,在文本字符写入结束后,自动调用了一次newLine()方法插入换行符。
public class PrintWriterDemo {
public static void main(String[] args) {
try (PrintWriter pw = new PrintWriter(new FileWriter("D://test/target.txt"))) {
// 自动添加换行符
pw.println("2024,加油努力干");
// 空行
pw.println();
// 自动添加换行符
pw.println("2024,加油努力干");
} catch (IOException e) {
e.printStackTrace();
}
}
}
缓冲流
Java非缓冲流的每次读写都需要进行本地方法调用,交给底层操作系统进行处理,工作效率非常低,因为每次请求可能都会触发磁盘读写、网络活动以及其它一些开销昂贵的操作。为了减少操作系统的负载,Java提供了IO缓冲流,缓冲流内部提供了缓冲区(buffer)进行读写,大部分缓冲流的buffer默认大小为8192字节(8KB)。
缓冲输入流从内存区域的buffer读取数据,当buffer数据为空时,Java本地输入方法才会进行调用。
缓冲输出流将数据写入到内存区域的buffer,当buffer写满时,Java本地输出方法才会进行调用。
Java程序可以通过包装方式将非缓冲流构造成为一个缓冲流,BufferedInputStream、BufferedOutputStream用于构造缓冲字节流,BufferedReader、BufferedWriter用于构造缓冲字符流。
字节缓冲流
字节缓冲流主要包括缓冲输入流BufferedInputStream,缓冲输出流BufferedOutputStreamWriter。
BufferedInputStream通过非缓冲字节流FileInputStream进行一次磁盘IO,一次性读取多个字节数据到内存buffer(字节数组),后续程序只需从内存中的buffer数组中读取字节数据,减少IO操作次数。
public class BufferedInputStreamDemo {
public static void main(String[] args) {
try (BufferedInputStream bis = new BufferedInputStream(
new FileInputStream("D://test/source.txt"))) {
int c;
// 从内存buffer中读取字节数据,如果buffer为空,才会进行IO操作
while((c = bis.read()) != -1) {
System.out.println(c);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
BufferedInputStream通过FileInputStream提供的本地方法readBytes,可以通过一次IO操作读取多个字节数据。

BufferedOutputStream通过非缓冲字节流FileOutputStream进行一次磁盘IO,将内存缓冲区buffer中的多个字节数据一次性写入文件中,减少IO操作次数。
public class BufferedOutputStreamDemo {
public static void main(String[] args) {
try (BufferedOutputStream bos = new BufferedOutputStream(
new FileOutputStream("D://test/target.txt"))) {
// 写入字符 '2' 到内存buffer
bos.write(50);
// 写入字符 '0' 到内存buffer
bos.write(48);
// 写入字符 '2' 到内存buffer
bos.write(50);
// 写入字符 '3' 到内存buffer
bos.write(51);
// 可在此 sleep 10s,去检测文件内容, 10s后调用了flush方法文件内容才写入
// try {
// Thread.sleep(10000);
// } catch (Exception e) {
// e.printStackTrace();
// }
// 刷新输出流,将内存buffer数据写到文件中
// 缓冲流的close方法调用时,会先自动调用一次flush方法,强制将数据写出
// 但是明确后续没有数据可写时,最好养成良好习惯,手动调用一次flush方法
bos.flush();
} catch (IOException e) {
e.printStackTrace();
}
}
}
BufferedOutputStream此时依赖的方法是非缓冲字节流FileOutputStream提供的本地方法writeBytes。

字符缓冲流
字符缓冲流主要包括缓冲输入流BufferedReader,缓冲输出流BufferedWriter。
BufferedReader可基于InputStreamReader、FileReader等非字符缓冲流构造。
public class BufferedReaderDemo {
public static void main(String[] args) {
try (BufferedReader br = new BufferedReader(new FileReader("D://test/source.txt"))) {
String line;
// 按行读取,自动处理回车换行符
while((line = br.readLine()) != null) {
System.out.println(line);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
基于FileReader构造BufferedReader
BufferedReader br = new BufferedReader(new FileReader("D://test/source.txt"))
BufferedWriter可基于OutputStreamReader、FileWriter等非字符缓冲流构造。
public class BufferedWriterDemo2 {
public static void main(String[] args) {
try (BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(
new FileOutputStream("D://test/target.txt")))) {
bw.write("2024,加油努力干");
// windows换行符
// bw.write("\r\n");
bw.newLine();
bw.write("2024,加油努力干");
bw.flush();
} catch (IOException e) {
e.printStackTrace();
}
}
}
基于FileWriter构造BufferedWriter
BufferedWriter bw = new BufferedWriter(new FileWriter("D://test/target.txt"))
基于PrintWriter构造BufferedWriter
BufferedWriter bw = new BufferedWriter(new PrintWriter(new FileWriter("D://test/target.txt")))
flush方法是属于输出流的方法,调用非缓冲流的flush方法不会产生任何作用。